Machine Learning Basics
Learning Algorithms
Definition
一个计算机程序以Performace P从有关Task T的Experience E中学习
Description
- Example
-
Feature(被量化的特征)的集合
-
$x\in\R^n$,每一个$x_i$都是一个feature
- 通过计算机处理Example的方式来定义Machine Learning
Common Tasks that can be done by Machine Learning
-
Classification(With Missing Inputs)
-
Regression(回归)
- 预测
- Transcription
- 把无序的数据变成固定的、有序的形式
Translation
Performace Measure P
- Accuracy
- 正确输出的比例
- Error Rate
- 错误输出的比例
Experience E
- Unsupervised Learning Algorithms
- 学习$\pmb x$并得到它的$p(\pmb x)$
- Supervised Learning Algorithms
- 学习$\pmb{x和y}$,并最终通过$\pmb x$预测$\pmb y$
- 以上两个术语并不是严格定义的
Linear Regression
$$ \hat y =\pmb{w^Tx} + b\\\ \\ MSE_{test} = \frac{1}{m}\sum_i(\pmb {\hat y}{test} - \pmb y{test})^2_i = \frac{1}{m}||\pmb {\hat y}{test} - \pmb y{test}||2^2 \\\ \\ To \ minimize, \ \nabla\omega \frac{1}{m} ||\hat {\pmb y}^{(train)} - \pmb y^{(train)} ||2^2 = 0 \\\ \\ \nabla\omega \frac{1}{m} || \pmb X^{(train)}\pmb w - \pmb y^{(train)} ||_2^2 = 0 \\\ \\ \nabla_w (\pmb X^{(train)}\pmb w - \pmb y^{(train)})^T (\pmb X^{(train)}\pmb w - \pmb y^{(train)}) = 0 \\\ \\ \pmb w = (\pmb X^{(train)T}\pmb X^{(train)})^{-1} \pmb X^{(train)T}y^{(train)} $$
- 满足上述条件的叫做Normal Equation
Capacity, Underfitting, Overfitting
Introduction
-
Generalization: 预测数据的能力
-
Data generating distribution$p_{data}$
-
Training Error and Test Error
-
Training Error通常比Test Error低
-
Test Error是更重要的评估指标
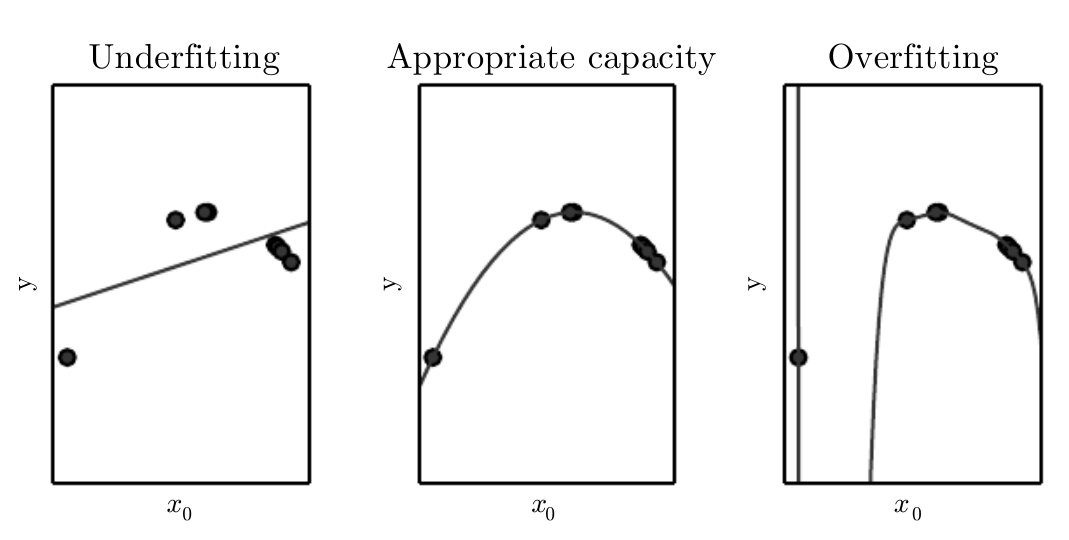
Underfitting Overfitting Capacity
- Underfitting Overfitting
| Underfitting | Overfitting |
|---|---|
| 两种误差都很高 | Training Error高,Test Error低 |
- Capacity
-
训练模型适应新数据的能力
-
以下示例对应一次,2次,9次多项式模型
- Adjust Capacity
-
调整参数
-
增加数据量大小
-
换训练模型
Non-parametric Model ; Bayes Error
- Non-parametric Model
- 它在训练数据集中找到与新数据点最接近的k个数据点,然后将它们的输出值进行加权平均,作为新数据点的输出值。
$$ When \ i = min||\pmb X_i -\pmb x||_2^2: \ \hat y = y_i $$
- Bayes Error
- 在一个分类问题中,使用任何算法所能达到的最小错误率
$$ P(error) = 1 - P(correct) = 1 - \int_{\mathcal{X}} P(correct|x)P(x)dx \\\ \\ \mathcal X是样本分布 \ \ P(correct): 正确分类的概率 $$
Regularization
- Weight Dacay
$$ J(\pmb \omega) = MSE_{(train)} + \lambda\omega^T \omega \\\ \\ \lambda: Orthogonal \ parameter \\\ \\ \omega \uparrow \Longrightarrow J \uparrow \Longrightarrow 过拟合\downarrow $$
- Regularizer
-
在Weight Decay中,$\pmb{\Omega(\omega) = \omega^T\omega}$
-
Regularization是通过优化模型降低其Generalization Error,而不是Test Error
Hyperparameters and Cross-Validation
Hyperparameters
- 训练前设置好的参数
Cross-Validation
- 定义
Cross-validation是一种评估机器学习模型性能的技术,它将数据集分成训练集和验证集,并使用不同的训练集和验证集组合来评估模型的性能。在交叉验证中,数据集被分成k个相等的子集,其中一个子集被保留用于验证模型,而其他k-1个子集被用于训练模型。这个过程重复k次,每次使用不同的子集作为验证集。最终,交叉验证会生成k个模型,每个模型都被评估一次,然后将这些评估结果的平均值作为模型的性能评估指标。
- k-fold Cross-Variance Algorithm
|
|
Bias and Variance
Bias & MSE
$$ bias(\hat{\pmb \theta}_m) = \mathbb E(\hat{\pmb \theta}_m) - \pmb \theta \\\ \\ \begin{aligned} MSE &= \mathbb E[(\hat{\pmb \theta}_m - \pmb \theta)^2] \\ & = Bias^2(\hat{\pmb \theta}) + Var(\hat{\pmb \theta}) \end{aligned} $$
Supervised Learning Algorithm
Category
- SVM (Support Vector Machine) - Binary Problem
- $y$与kernel
$$ \begin{aligned} f(\pmb x) &= \pmb{w^Tx} + b = b + \sum_{i=1}^n \alpha_i \pmb{x^Tx^{(i)}} \\ &= b + \sum_i k(\pmb{x,x^{i}}) \end{aligned} \\\ \\ Gaussian \ Kernal: k(\pmb{u,v}) = \mathcal N (u-v;0.\sigma^2\pmb I) \ \ \ \\\ \\ Also \ known \ as \ \pmb{RBF(radical \ basis function)} $$
Unsupervised Learning Algorithm
Principal Component Analysis (PCA)
- 详见Linear Algebra
K-means Clustering
$$ J(\theta) = \mathbb E $$
Gradient Descent
定义
不断地沿梯度方向前进,逐渐减小函数值的过程
迭代公式
$$ \theta = \theta - \alpha \nabla J(\theta) \\\ \\ \nabla J(\theta) = \begin{pmatrix} \frac{\partial J}{\partial \theta_1} \\ \frac{\partial J}{\partial \theta_2} \\ … \\ \frac{\partial J}{\partial \theta_n} \end{pmatrix} \\\ \\ \theta: 优化参数 \ \ \alpha:学习率 \ \ J: 目标参数 $$
-
学习率过大,结果会超大
-
学习率过小,结果几乎没有改变
思想
沿着梯度的负方向更新参数,求得函数的最小值
Challenges
-
计算资源和时间成本
-
数据偏差和公平性
Deep Learning
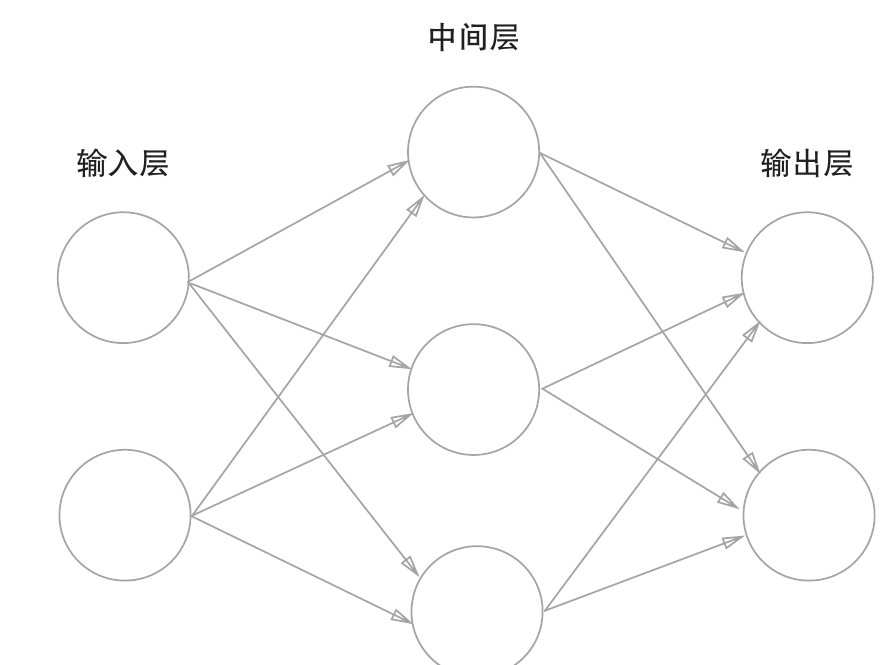
神经网络
图示
解释
-
中间层又被称为隐藏层
-
用第0,1,2层表示输入、中间、输出层
示例
图示——含有偏置的简单神经网络
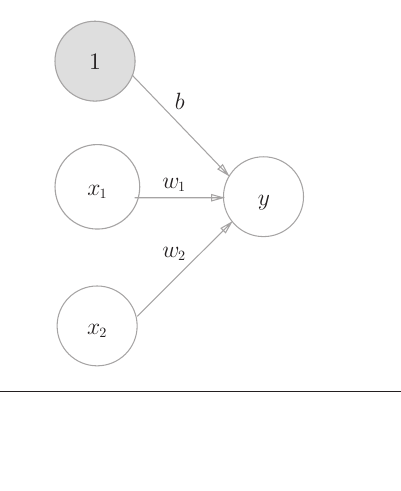
$$ y = \begin{cases} 0 & w_1x_1 + w_2x_2 + b \le 0 \\ 1 & w_1x_1 +w_2x_2 + b \gt 0 \end{cases} \\\ \\ 引入\pmb{激活函数h(x)}=\begin{cases} 1 & x\gt 0 \\ 0 & x\le 0 \end{cases} \\\ \\ 那么y = h(w_1x_1 + w_2x_2 + b) \\\ \\ 此处的激活函数是一种\pmb{阶跃函数} \\\ \\ \pmb{阶跃函数} 是感知机的激活函数 $$
进一步推导
- 图示
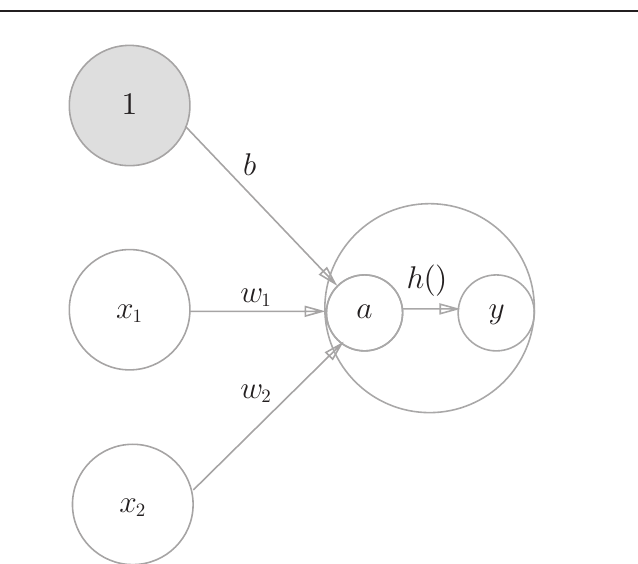
$$ a = w_1x_1 + w_2x_2 + b \\\ \\ y = h(a) $$
激活函数
sigmoid函数
$$ h(x) = \frac{1}{1+e^{-x}} $$
比较
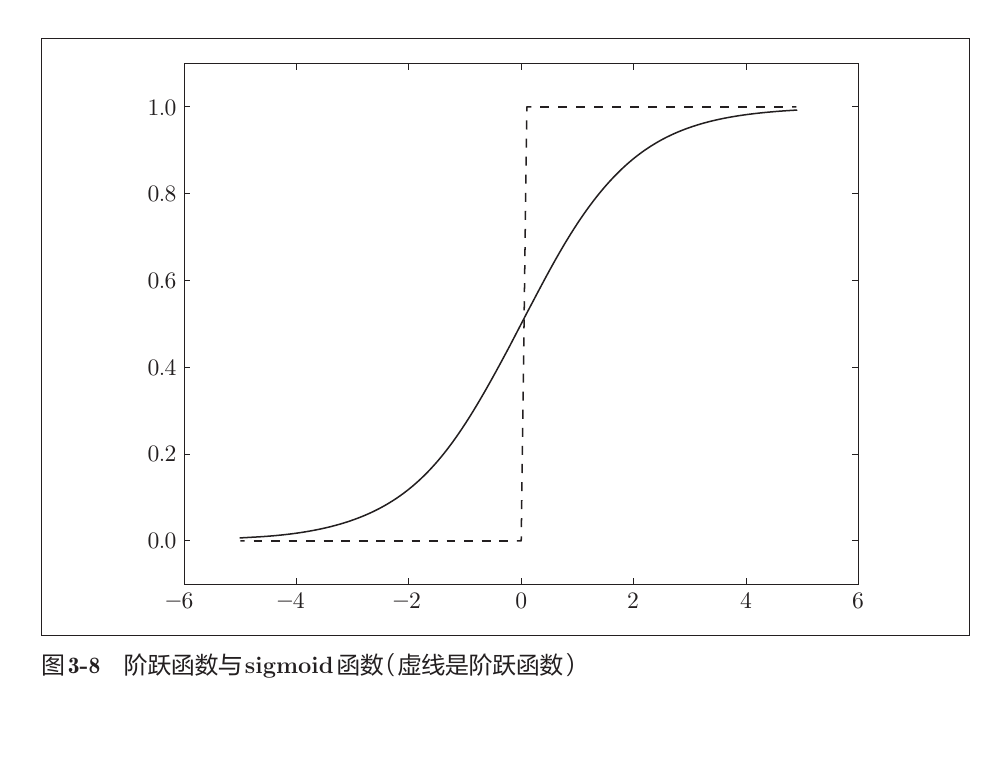
- 共同点
-
输出信号始终$\in(0,1)$
-
输入重要信息,输出较大的值
-
均为非线性函数
- 不同点
- Sigmoid平滑,而阶跃函数突变
ReLU - Rectified Linear Unit
$$ h(x) = \begin{cases} x & x \gt 0 \\ 0 & x \le 0 \end{cases} $$
神经网络的内积
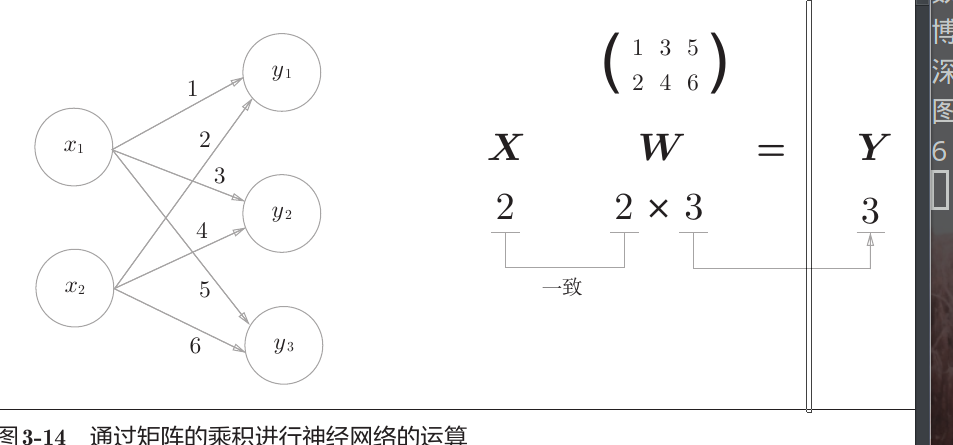
三层神经网络的实现
权重的符号
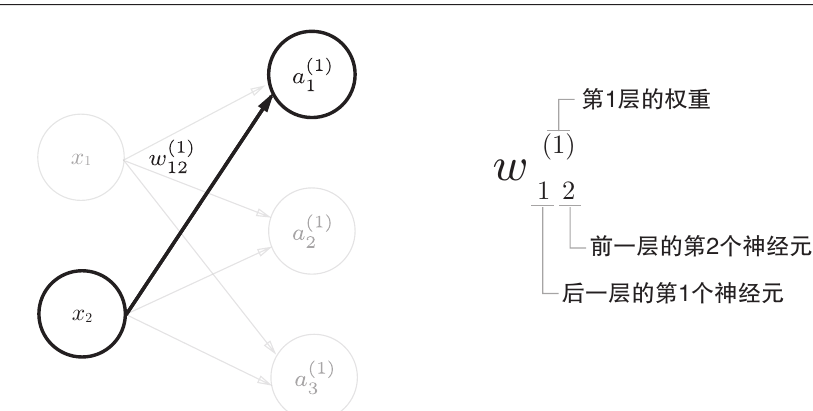
实现
$$ a_1^{(1)} = x_2w_{12}^{(1)} + x_1w_{11}^{(1)}+b_1^{(1)} \\\ \\ A^{(1)} = XW^{(1)} + B^{(1)} \\\ \\ 其中,A^{(1)} = \begin{pmatrix} a_1^{(1)} & a_2^{(1)} & a_3^{(1)} \end{pmatrix} \\\ \\ X = \begin{pmatrix} x_1 & x_2 \end{pmatrix} \\\ \\ W^{(1)} = \begin{pmatrix} w_{11}^{(1)} & w_{21}^{(1)} & w_{31}^{(1)}\\ w_{21}^{(1)} & w_{22}^{(1)} & w_{23}^{(1)} \end{pmatrix} \\\ \\ B^{(1)} = \begin{pmatrix} b_1^{(1)} & b_2^{(1)} & b_3^{(1)} \end{pmatrix} $$
输出层的设计
回归问题 —— 恒等函数
$$ h(x) = x \ \ x \in R $$
上述代码总和
|
|
神经网络的学习
损失函数
均方误差
$$ E = \sum_k\frac{1}{2}(y_k - t_k)^2 \\\ \\ t_k:训练数据 \ \ y_k:输出 \ \ k:维数 $$
交叉熵误差
$$ E = - \sum_k t_k \cdot ln(y_k) $$
mini-batch学习
- 定义
从大量数据中随机选取小批量数据进行学习
- 损失函数总和 (以交叉熵误差为例)
$$ E = -\frac{1}{N}\sum_k \sum_k t_{nk} \ ln(y_{nk}) $$
数学知识补充
数值微分
$$ \frac{df(x)}{dx} = \frac{f(x+h)-f(x-h)}{2h} \\\ \\ 通过\pmb{中心差分}实现更高的\pmb{精度} $$